SemanticAlignNet_old
A Semantic Segmentation-guided Approach for Ground-to-Aerial Image Matching
This refers to "A Semantic Segmentation-guided Approach for Ground-to-Aerial Image Matching". It procudes our results on a subset of the CVUSA dataset.
Abstract
Nowadays the accurate geo-localization of ground-view images has an important role across different domains, including journalism, forensics analysis, and Earth Observation. This work addresses the problem of matching a query ground-view image with the corresponding satellite image without GPS data. This is done by comparing the features from a ground view image with a satellite one together with its segmentation mask through a three-stream Siamese-like network. The proposed method focuses on limited Field-of-View (FoV) and ground panorama images (images with a FoV of 360°). The novelty is in the fusion of satellite images in combination with their segmentation masks, aimed at ensuring that the model can extract features and focus on the significant parts of the images. This work shows how the proposed model through semantic segmentation mask images improves the performance on the unlabelled CVUSA dataset on all the tested FoV.
Model
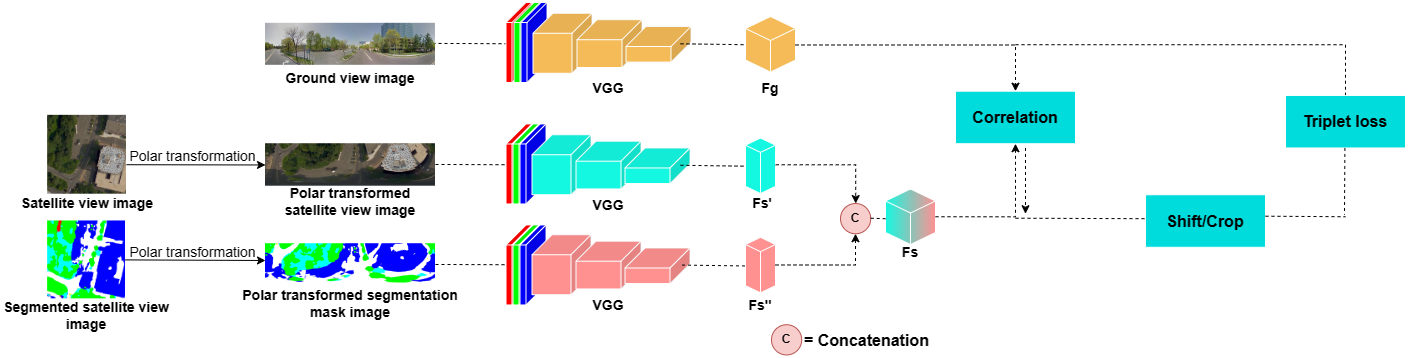
Requirements
- This code uses
TensorFlow 2.10.0numpy 1.25.2cv2 4.8.0and run on modern GPU of at least 6GB of memory - We run the code with
Python 3.9.2 - Download the used CVUSA subset at the following link:
- https://drive.google.com/file/d/17W9VEPMneRlb6igtSxa–Xh4fSZs3RS_/view?usp=sharing
Steps
- Clone this repository
git clone https://github.com/pro1944191/SemanticAlignNet
- For training run the following command from the shell:
python train_no_session.py --train_grd_noise 360 --train_grd_FOV $YOUR_FOV --test_grd_FOV $YOUR_FOV- This command will run the python file
train_no_session.py, inside it there are other possible parameters to pass as input or to leave as default value $YOUR_FOVchoose a value bewteen 0° and 360°, that is the FoV value used for the ground view images- The trained model will be saved in the path
./saved_models/model_name/, will be created a folder for each trained epoch and a.txtfile with a recap of the training
- For testing run the following command from the shell:
python test_no_session.py --train_grd_noise 360 --train_grd_FOV $YOUR_FOV --test_grd_FOV $YOUR_FOV- This command will run the python file
test_no_session.py, inside it there are other possible parameters to pass as input or to leave as default value $YOUR_FOVchoose a value bewteen 0° and 360°, that is the FoV value used for the ground view images- The results of the testing phase will be saved in a
.matfile
- Dataset
- Once you downloaded the dataset you will have the following folders:
Streetviewthis folder contains the ground view images (streetview)Bingmapthis folder contains the original satellite view imagesSegmaphere are contained the original segmented mask imagesPolarmap//normalthis subfolder contains the polar transformed satellite images/segmapthis subfolder contains the polar transformed segmetation mask images
- Once you downloaded the dataset you will have the following folders: